Top-Down Map Fuser
Concatenates RGB, occupancy, and semantic map representations before patch embedding to form a joint spatial input.
One-Step Global Planning for Vision-Language Navigation on Top-Down Maps
NavOne reformulates Vision-Language Navigation as one-step global path planning over pre-built top-down RGB, occupancy, and semantic maps, directly predicting dense path and goal probabilities in a single forward pass.
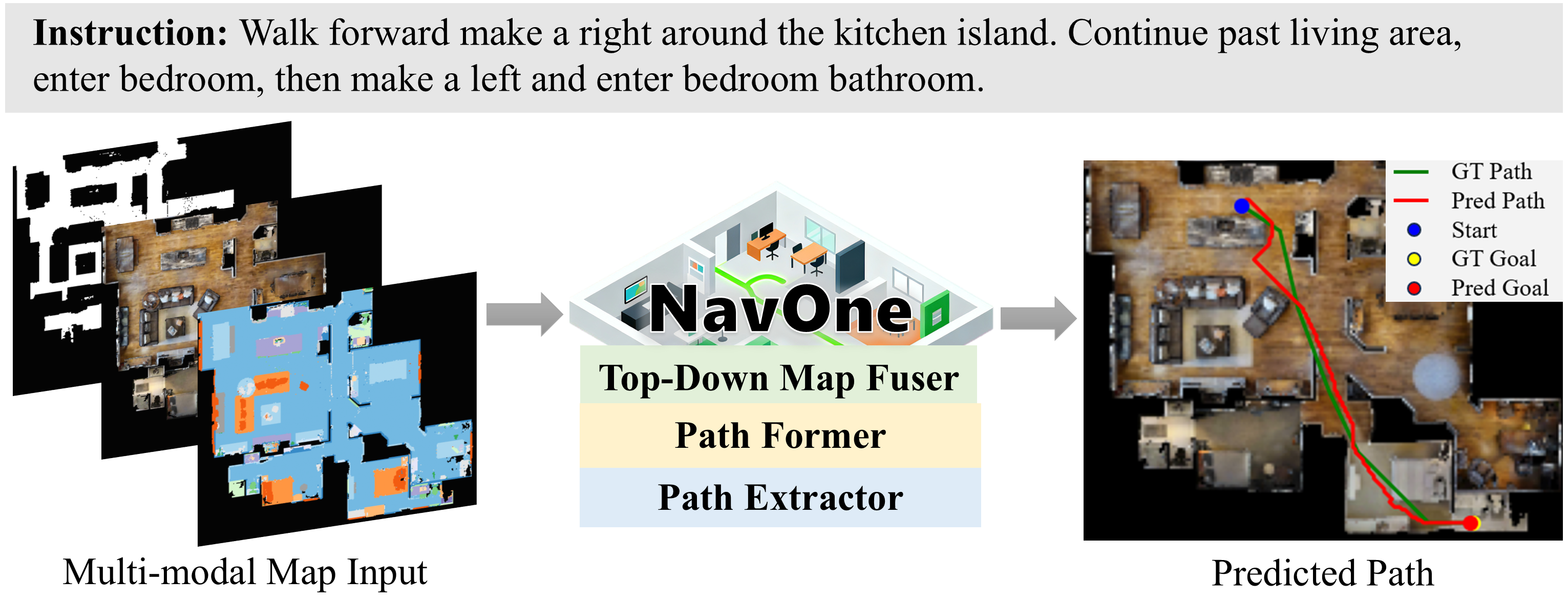
Overview
Existing VLN systems commonly act from egocentric observations one step at a time, which can accumulate errors and limits planning efficiency. NavOne introduces Top-Down VLN, where an agent predicts a complete navigation path from a language instruction and a pre-built top-down map.
The model processes RGB, occupancy, and semantic map layers jointly, grounds the instruction with spatial features, and produces interpretable path and goal probability maps that are converted into an executable trajectory.
Method
The framework combines map fusion, language-conditioned spatial reasoning, and symbolic path extraction into a single global planning pipeline.
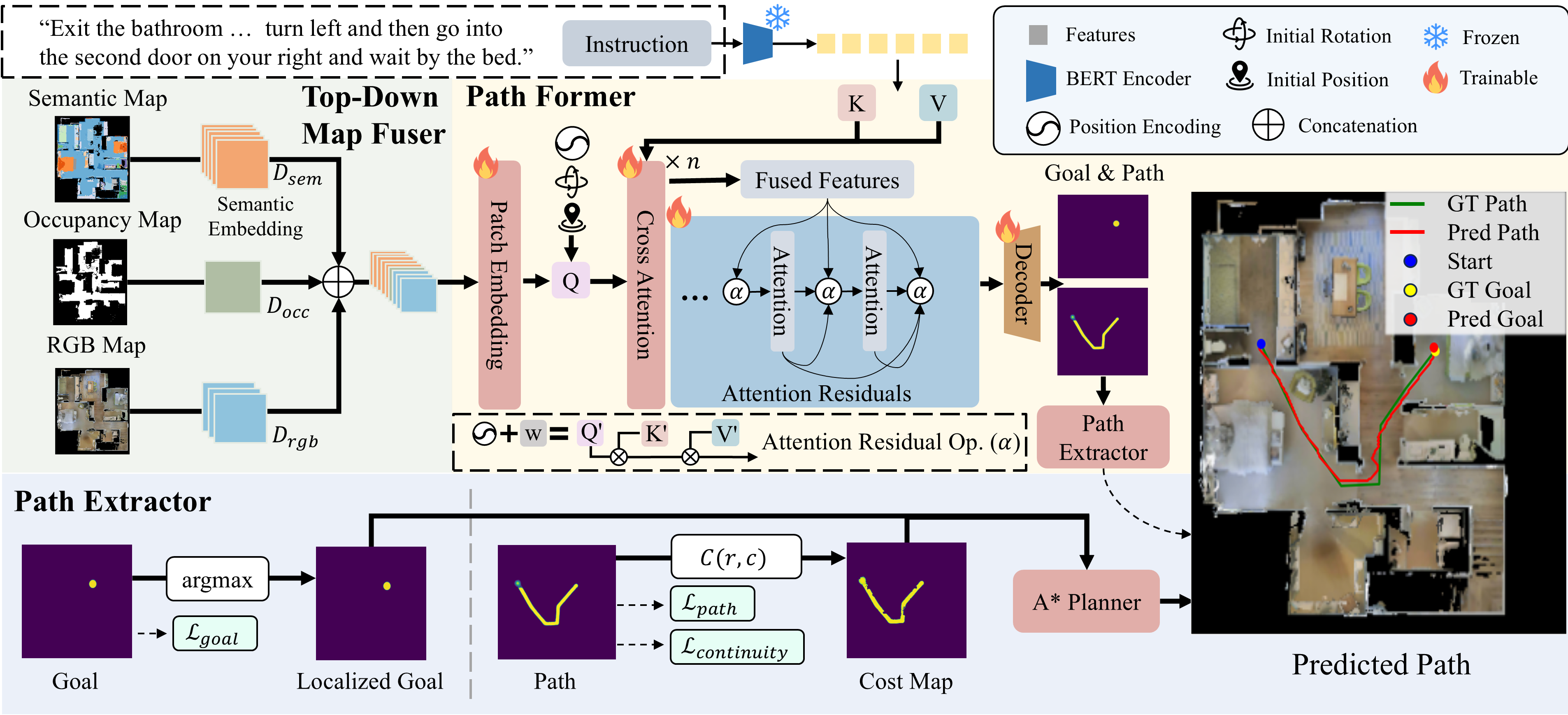
Concatenates RGB, occupancy, and semantic map representations before patch embedding to form a joint spatial input.
Integrates pose, language, and fused map tokens with cross-attention and spatial-aware Attention Residuals.
Converts predicted path and goal probability maps into an executable navigation trajectory through A* search.
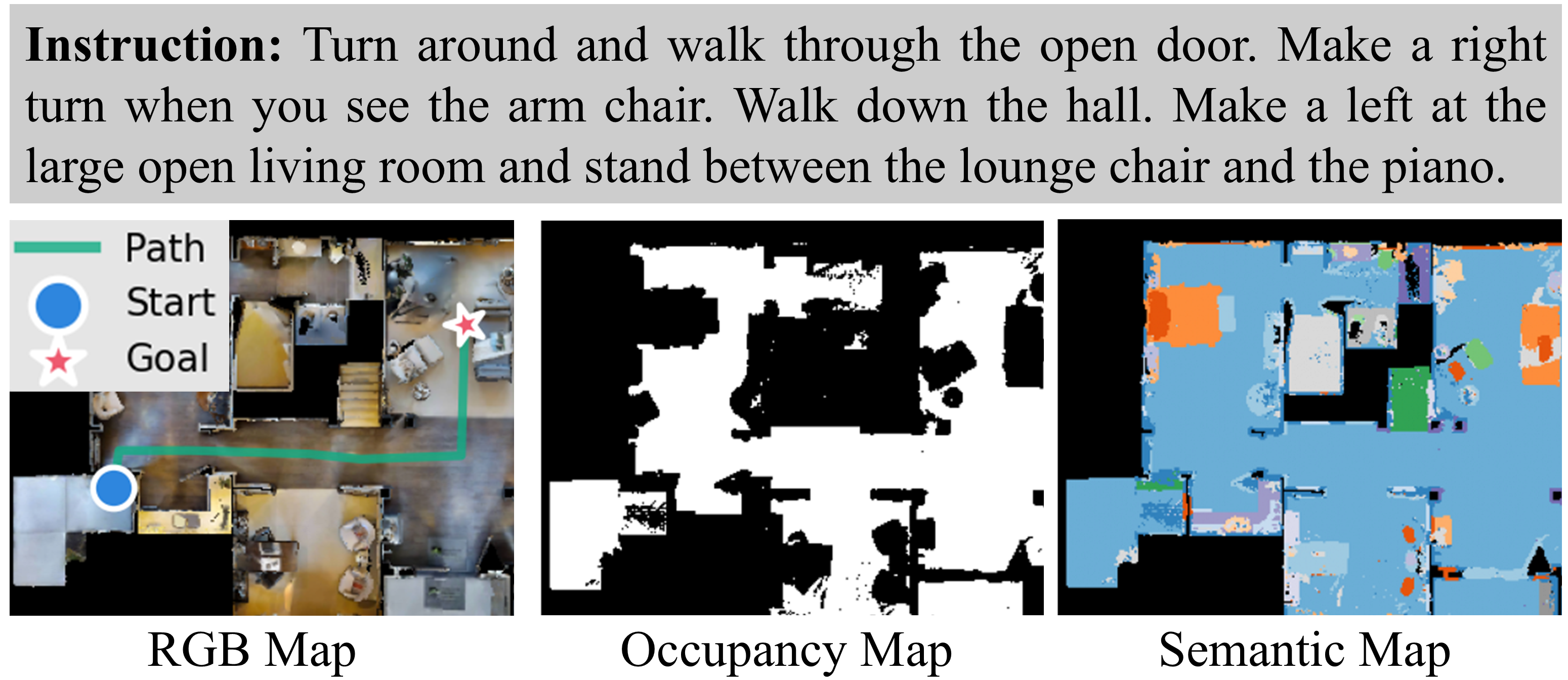
R2R-TopDown
R2R-TopDown transfers single-floor R2R-CE trajectories to top-down map representations. Each episode includes a language instruction, start pose, RGB map, occupancy map, semantic map with 41 object categories, and trajectory target.
| Split | Samples | Path Length | Instruction Length |
|---|---|---|---|
| Train | 6,196 | 9.58 m | 26.5 |
| Val Seen | 439 | 9.92 m | 27.3 |
| Val Unseen | 1,003 | 9.83 m | 26.8 |
Results
Primary metrics: Val Unseen SR/SPL. NavOne improves these success metrics on the filtered R2R-TopDown Val Unseen subset while reducing planning time to 37 ms per episode.
| Method | Seen SR | Seen SPL | Unseen SR | Unseen SPL | Unseen TL | Unseen NE |
|---|---|---|---|---|---|---|
| WS-MGMap | 0.47 | 0.43 | 0.39 | 0.34 | 10.00 | 6.28 |
| MapNav | - | - | 0.40 | 0.37 | - | 4.93 |
| IPPD | 0.57 | 0.54 | 0.45 | 0.42 | - | - |
| IPPD* | - | - | 0.37 | 0.31 | - | - |
| NavOne (AR-Full+SQ) | 0.57 | 0.50 | 0.47 | 0.43 | 9.20 | 5.18 |
WS-MGMap, MapNav, and IPPD report on full R2R Val Unseen episodes. IPPD* and NavOne are evaluated on the filtered R2R-TopDown Val Unseen subset of 1,003 single-floor episodes, so direct numerical comparisons with NavOne should be interpreted with caution.
The final AR-Full+SQ model is selected for stronger generalization on unseen maps. Standard attention performs best on Val Seen, while spatial-aware depth queries provide the highest Val Unseen SR/SPL.
| Variant | Seen SR | Seen SPL | Unseen SR | Unseen SPL | Unseen TL | Unseen NE |
|---|---|---|---|---|---|---|
| NavOne (Std. Attn) | 0.63 | 0.55 | 0.40 | 0.36 | 10.45 | 6.00 |
| NavOne (AR-Full) | 0.59 | 0.52 | 0.44 | 0.40 | 9.50 | 5.40 |
| NavOne (AR-Full+SQ) | 0.57 | 0.50 | 0.47 | 0.43 | 9.20 | 5.18 |
Planning times are measured end-to-end from instruction input to executable path output on the same NVIDIA 4090D GPU. The ETPNav comparison reflects planning speed under the pre-built-map assumption.
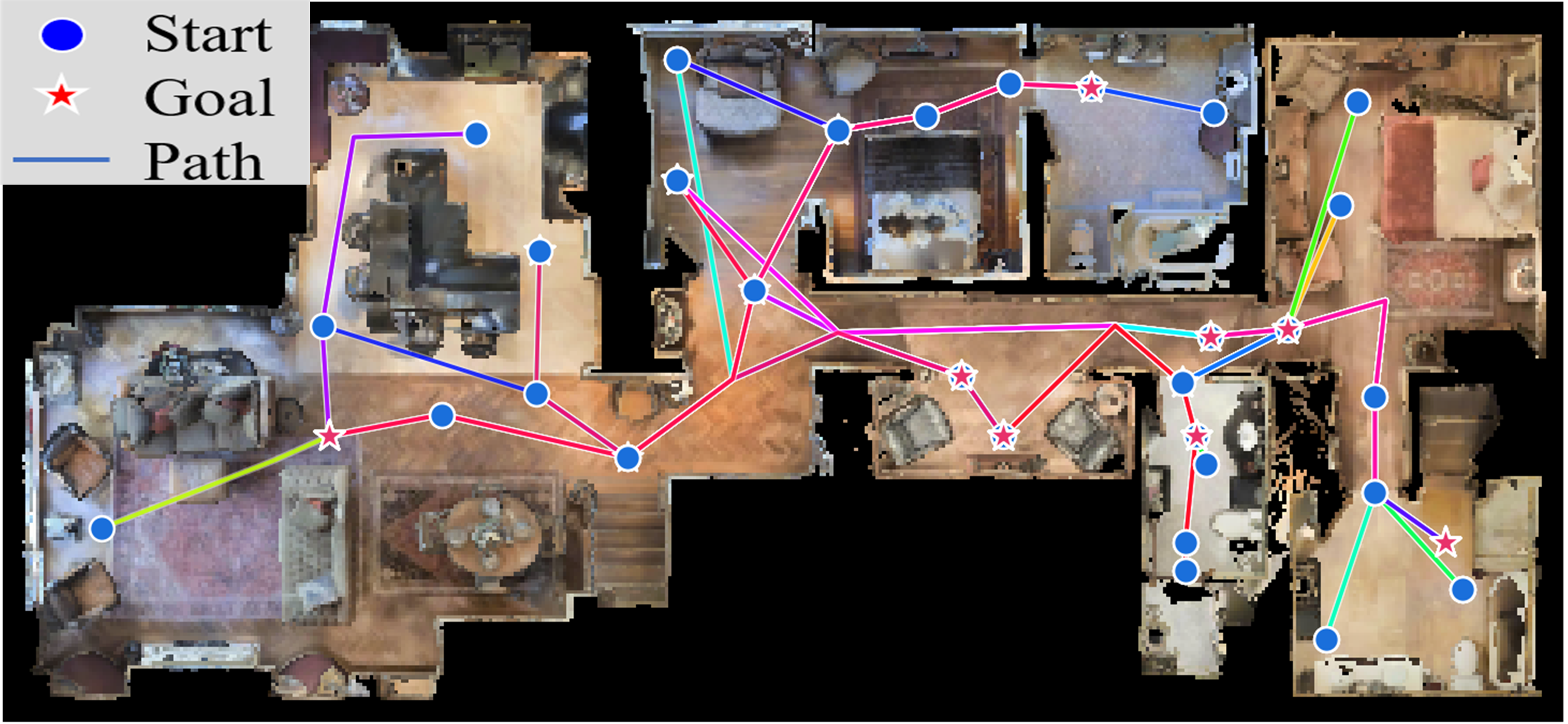
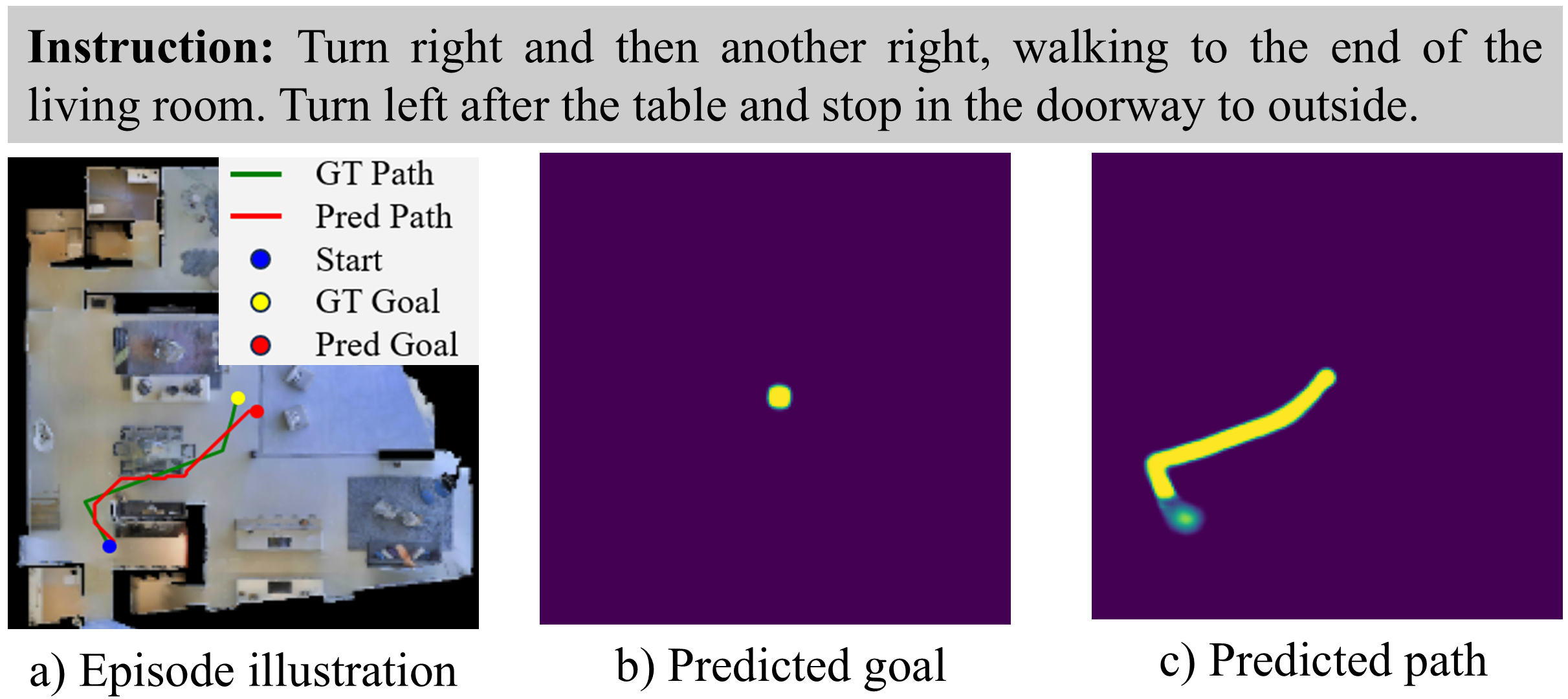
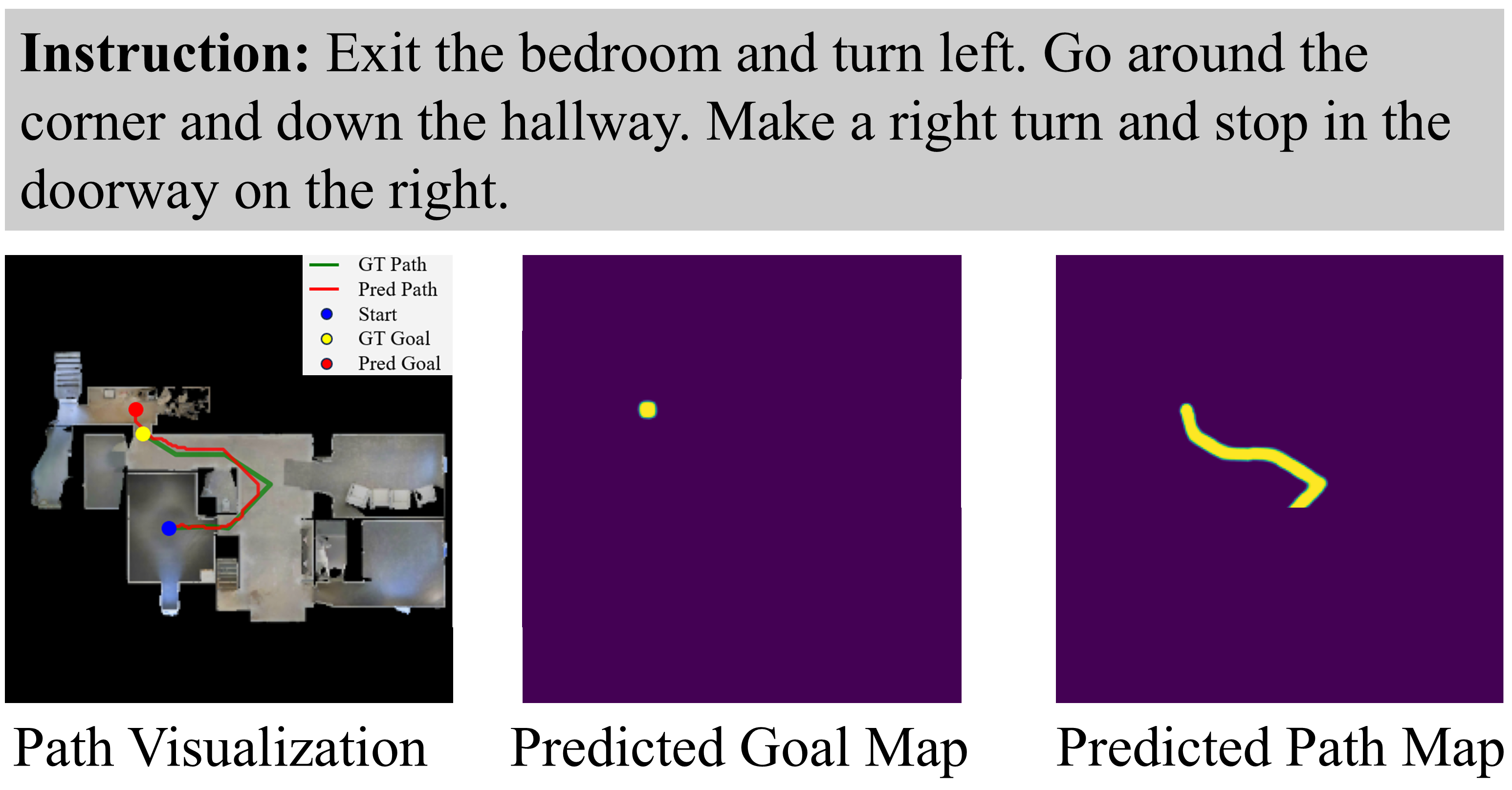
Qualitative Gallery





Citation
The paper is available as arXiv:2605.06317.
@article{zhan2026navone,
title = {NavOne: One-Step Global Planning for Vision-Language Navigation on Top-Down Maps},
author = {Zhan, Dijia and Li, Jinyi and Zheng, Chenxi and Huang, Shaoyu and Li, Yong and Tang, Jie and Xu, Xuemiao},
journal = {arXiv preprint arXiv:2605.06317},
year = {2026}
}